はじめに
アラートポリシーの料金モデル
- アラートポリシーの条件あたり月額 $ 0.10
- 指標アラートポリシー条件のクエリによって返される 1,000,000 時系列あたり $ 0.35
アラートポリシー費用削減戦略
- 100条件×月額 $ 0.10 = 月額 $ 10 = 月額 1,500円($ 1 = 150円と定義)
- 1条件×月額 $ 0.10 = 月額 $ 0.10 = 月額 15円
Terraformで実装
統合前のアラートポリシーソース
全体ソース
alert.tf
data "google_compute_instance" "vm" {
for_each = toset(var.alert_target)
name = ${each.value}
zone = "asia-northeast1-a"
}
data "google_monitoring_notification_channel" "all" {
for_each = toset(var.notification_channels)
project = var.project
display_name = each.value
}
resource "google_monitoring_alert_policy" "alert_cpu" {
for_each = toset(var.alert_target)
project = var.project
display_name = "[${each.value}] VM checking cpu utilization"
combiner = "OR"
conditions {
display_name = "[${each.value}] VM checking cpu utilization"
condition_threshold {
filter = "metric.type = \"compute.googleapis.com/instance/cpu/utilization\" AND resource.labels.instance_id=\"${data.google_compute_instance.vm[each.value].instance_id}\" AND resource.type=\"gce_instance\""
duration = "120s"
comparison = "COMPARISON_GT"
threshold_value = 0.9
trigger {
count = 1
}
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
notification_channels = [for channel in data.google_monitoring_notification_channel.all : channel.name]
documentation {
content = "インスタンス(${each.value})のCPU使用率が高くなっています"
}
}
variable "alert_target" {
type = list(string)
}
variable "notification_channels" {
type = list(string)
}
terraform.tfvars
alert_target = ["vm1", "vm2", "vm3"]
notification_channels = ["通知チャネル1", "通知チャネル2"]
filter
filter = "metric.type = \"compute.googleapis.com/instance/cpu/utilization\" AND resource.labels.instance_id=\"${data.google_compute_instance.vm[each.value].instance_id}\" AND resource.type=\"gce_instance\""
aggregations
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_MEAN"
} documentation
documentation {
content = "インスタンス(${each.value})のCPU使用率が高くなっています"
}
統合後のアラートポリシーソース
全体ソース
alert.tf
data "google_monitoring_notification_channel" "all" {
for_each = toset(var.notification_channels)
project = var.project
display_name = each.value
}
resource "google_monitoring_alert_policy" "alert_cpu" {
project = var.project
display_name = "VM checking cpu utilization"
combiner = "OR"
conditions {
display_name = "VM checking cpu utilization"
condition_threshold {
filter = "metric.type = \"compute.googleapis.com/instance/cpu/utilization\" AND resource.labels.project_id=\"${var.project}\" AND resource.type=\"gce_instance\""
duration = "120s"
comparison = "COMPARISON_GT"
threshold_value = 0.9
trigger {
count = 1
}
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_MEAN"
group_by_fields = ["metadata.system_labels.name"]
cross_series_reducer = "REDUCE_MEAN"
}
}
}
notification_channels = [for channel in data.google_monitoring_notification_channel.all : channel.name]
documentation {
content = "インスタンス($${metadata.system_labels.name})のCPU使用率が高くなっています"
}
}
variable "notification_channels" {
type = list(string)
}
terraform.tfvars
notification_channels = ["通知チャネル1", "通知チャネル2"]filter
filter = "metric.type = \"compute.googleapis.com/instance/cpu/utilization\" AND resource.labels.project_id=\"${var.project}\" AND resource.type=\"gce_instance\""
metadata.system_labels.name = one_of(\"${google_compute_instance.<ローカル名>.name}\", \"${google_compute_instance.<ローカル名>.name}\", \"${google_compute_instance.<ローカル名>.name}\"aggregations
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_MEAN"
group_by_fields = ["metadata.system_labels.name"]
cross_series_reducer = "REDUCE_MEAN"
}documentation
documentation {
content = "インスタンス($${metadata.system_labels.name})のCPU使用率が高くなっています"
}
アラートの確認
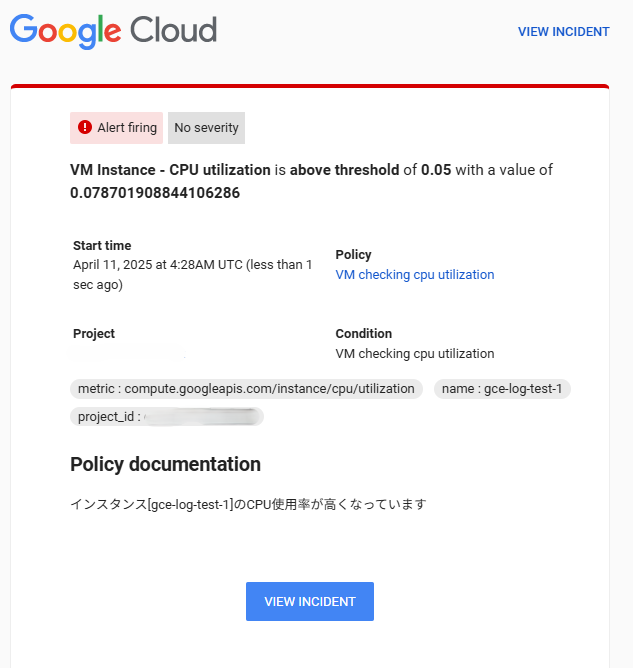
まとめ
- filter:1つのVMからプロジェクト内の全VMに範囲を拡大
- aggregations:グループ化設定追加でmetadata変数を使用可能にする
- documentation:metadata変数を使用してリソース名を表示
参考
- アラートの費用を管理する 【Google公式ドキュメント】
- アラートの料金 【Google公式ドキュメント】
- アラートポリシー 【Terraform公式ドキュメント】
- 選択した時系列をフィルタする 【Google公式ドキュメント】
- ドキュメント変数【Google公式ドキュメント】
- null個の値【Google公式ドキュメント】
Google Cloud、Google Workspace に関するご相談はXIMIXへ!
Google Cloud、Google Workspaceに関する お問い合わせはこちら
執筆者紹介








![[GWSStudio100本ノック] Workspace Studio が NotebookLM 連携 ― Chat の問い合わせを AI が一次回答するデモ](https://ximix.niandc.co.jp/hs-fs/hubfs/Gemini_Generated_Image_r967l1r967l1r967.png?width=84&name=Gemini_Generated_Image_r967l1r967l1r967.png)
